Al diseñar mecanismos de planificación apropiativa no hay que perder de
vista la arbitrariedad de casi todos los sistemas de prioridades. Se
puede construir un mecanismo complejo para implantar fielmente un
esquema de apropiación por prioridades sin que, de hecho, se hayan
asignado .
Planificacion de Procesos
A partir de aquí nos centraremos en la planificación a corto plazo o de la CPU. Discutiremos los principales objetivos y criterios a tener en cuenta a la hora de decidirnos por una determinada política de planificación. A continuación realizaremos una clasificación de estos criterios agrupándolos en apropiativos y no apropiativos. Hablaremos del reloj de interrupciones, con la intención de aclarar cómo es posible la intervención del sistema operativo para evitar la monopolización de la CPU por parte de los usuarios. Dedicaremos especial atención al mecanismo de planificación basado en prioridades. Terminaremos haciendo un estudio y evaluación cualitativa de los algoritmos de planificación que se pueden emplear. Durante este repaso haremos una reflexión sobre las repercusiones en cuanto a eficiencia y tiempo de respuesta del parámetro tamaño de cuanto.
Niveles de Planificación
La planificación de la CPU, en el sentido de conmutarla entre los distintos procesos, es una de las funciones del sistema operativo. Este despacho es llevado a cabo por un pequeño programa llamado planificador a corto plazo o dispatcher (despachador). La misión del dispatcher consiste en asignar la CPU a uno de los procesos ejecutables del sistema, para ello sigue un determinado algoritmo. En secciones posteriores estudiaremos algunos algoritmos posibles. Para que el dispatcher conmute el procesador entre dos procesos es necesario realizar un cambio de proceso.
Los acontecimientos que pueden provocar la llamada al dispatcher dependen del sistema (son un subconjunto de las interrupciones), pero son alguno de estos:
- El proceso en ejecución acaba su ejecución o no puede seguir ejecutándose (por una E/S, operación WAIT, etc).
-Un elemento del sistema operativo ordena el bloqueo del proceso en ejecución
-El proceso en ejecución agota su cuantum o cuanto de estancia en la CPU.
-Un proceso pasa a estado listo.
Hay que destacar el hecho de que cuanto menos se llame al dispatcher menos tiempo ocupa la CPU un programa del sistema operativo, y, por tanto, se dedica más tiempo a los procesos del usuario (un cambio de proceso lleva bastante tiempo).
Así, si sólo se activa el dispatcher como consecuencia de los 2 primeros acontecimientos se estará haciendo un buen uso del procesador. Este criterio es acertado en sistemas por lotes en los que los programas no son interactivos. Sin embargo, en un sistema de tiempo compartido no es adecuado, pues un proceso que se dedicara a realizar cálculos, y no realizara E/S, monopolizaría el uso de la CPU. En estos sistemas hay que tener en cuenta el conjunto de todos los procesos, activándose el dispatcher con la circunstancia tercera y, posiblemente, la cuarta. Los sistema operativos en que las dos siguientes circunstancias no provocan la activación del dispatcher muestran preferencia por el proceso en ejecución, si no ocurre esto se tiene más en cuenta el conjunto de todos los procesos.
Se puede definir el scheduling -algunas veces traducido como -planificación- como el conjunto de políticas y mecanismos construidos dentro del sistema operativo que gobiernan la forma de conseguir que los procesos a ejecutar lleguen a ejecutarse.
El scheduling está asociado a las cuestiones de:
- Cuándo introducir un nuevo proceso en el Sistema.
- Determinar el orden de ejecución de los procesos del sistema.
El scheduling está muy relacionado con la gestión de los recursos. Existen tres niveles de scheduling, , estos niveles son:
- Planificador de la CPU o a corto plazo.
- Planificador a medio plazo.
- Planificador a largo Plazo
Ya hemos hablado del planificador de la CPU, y en los subapartados posteriores se comentan los dos restantes:
Planificación a largo plazo
Este planificador está presente en algunos sistemas que admiten además de procesos interactivos trabajos por lotes. Usualmente , se les asigna una prioridad baja a los trabajos por lotes, utilizándose estos para mantener ocupados a los recursos del sistema durante períodos de baja actividad de los procesos interactivos. Normalmente, los trabajos por lotes realizan tareas rutinarias como el cálculo de nóminas; en este tipo de tareas el programador puede estimar su gasto en recursos, indicándoselo al sistema. Esto facilita el funcionamiento del planificador a largo plazo.
Normalmente, se invoca al planificador a largo plazo siempre que un proceso termina. La frecuencia de invocación depende, pues, de la carga del sistema, pero generalmente es mucho menor que la de los otros dos planificadores. Esta baja frecuencia de uso hace que este planificador pueda permitirse utilizar algoritmos complejos, basados en las estimaciones de los nuevos trabajos.
Planificación a Medio Plazo
En los sistemas de multiprogramación y tiempo compartido varios procesos residen en la memoria principal. El tamaño limitado de ésta hace que el número de procesos que residen en ella sea finito. Puede ocurrir que todos los procesos en memoria estén bloqueados, desperdiciándose así la CPU. En algunos sistemas se intercambian procesos enteros (swap) entre memoria principal y memoria secundaria (normalmente discos), con esto se aumenta el número de procesos, y, por tanto, la probabilidad de una mayor utilización de la CPU.
El planificador a medio plazo es el encargado de regir las transiciones de procesos entre memoria principal y secundaria, actúa intentando maximizar la utilización de los recursos. Por ejemplo, transfiriendo siempre a memoria secundaria procesos bloqueados, o transfiriendo a memoria principal procesos bloqueados únicamente por no tener memoria
Objetivos y Criterios de Planificación
El principal objetivo de la planificación a corto plazo es repartir el tiempo del procesador de forma que se optimicen algunos puntos del comportamiento del sistema. Generalmente se fija un conjunto de criterios con los que evaluar las diversas estrategias de planificación. El criterio más empleado establece dos clasificaciones. En primer lugar, se puede hacer una distinción entre los criterios orientados a los usuarios y los orientados al sistema. Los criterios orientados al usuario se refieren al comportamiento del sistema tal y como lo perciben los usuarios o los procesos. Uno de los parámetros es el tiempo de respuesta. El tiempo de respuesta es el periodo de tiempo transcurrido desde que se emite una solicitud hasta que la respuesta aparece en la salida. Sería conveniente disponer de una política de planificación que ofrezca un buen servicio a diversos usuarios.
Otros criterios están orientados al sistema, esto es, se centran en el uso efectivo y eficiente del procesador. Un ejemplo puede ser la productividad, es decir, el ritmo con el que los procesos terminan. La productividad es una medida muy válida del rendimiento de un sistema y que sería deseable maximizar.
Otra forma de clasificación es considerar los criterios relativos al rendimiento del sistema y los que no lo son. Los criterios relativos al rendimiento son cuantitativos y, en general, pueden evaluarse o ser analizados fácilmente. Algunos ejemplos son el tiempo de respuesta y la productividad. Los criterios no relativos al rendimiento son, en cambio cualitativos y no pueden ser evaluados fácilmente. Un ejemplo de estos criterios es la previsibilidad. Sería conveniente que el servicio ofrecido a los usuarios tenga las mismas características en todo momento, independientemente de la existencia de otros trabajos ejecutados por el sistema.
En particular, una disciplina de planificación debe:
Ser equitativa: debe intentar hacer una planificación justa, esto es, se debe tratar a todos los procesos de la misma forma y no aplazar indefinidamente ningún proceso. La mejor forma de evitarlo es emplear alguna técnica de envejecimiento; es decir, mientras un proceso espera un recurso, su prioridad debe crecer.
Ser eficiente: debe maximizar el uso de los recursos tales como intentar que la ocupación de la CPU sea máxima. Al mismo tiempo se debe intentar reducir el gasto extra por considerar que es trabajo no productivo. Normalmente el idear algoritmos eficientes supone invertir recursos en gestión del propio sistema.
Lograr un tiempo bueno de respuesta, es decir, que los usuarios interactivos reciban respuesta en tiempos aceptables.
Lograr un tiempo de proceso global predecible. Esto quiere decir que un proceso debe ejecutarse aproximadamente en el mismo tiempo y casi al mismo costo con independencia de la carga del sistema.
Elevar al máximo la productividad o el rendimiento, esto es, maximizar el número de trabajos procesados por unidad de tiempo. Eso supone, por un lado, dar preferencia a los procesos que ocupan recursos decisivos y, por otro, favorecer a los procesos que muestran un comportamiento deseable. En el primer caso conseguimos liberar el recurso cuanto antes para que esté disponible para un proceso de mayor prioridad. Con el segundo criterio escogemos a los procesos que no consumen muchos recursos dejándole al sistema mayor capacidad de actuación.
Estos criterios son dependientes entre sí y es imposible optimizar todos de forma simultánea. Por ejemplo, obtener un buen tiempo de respuesta puede exigir un algoritmo de planificación que alterne entre los procesos con frecuencia, lo que incrementa la sobrecarga del sistema y reduce la productividad. Por tanto, en el diseño de un política de planificación entran en juego compromisos entre requisitos opuestos; el peso relativo que reciben los distintos requisitos dependerá de la naturaleza y empleo del sistema.
Planificación Apropiativa y No apropiativa
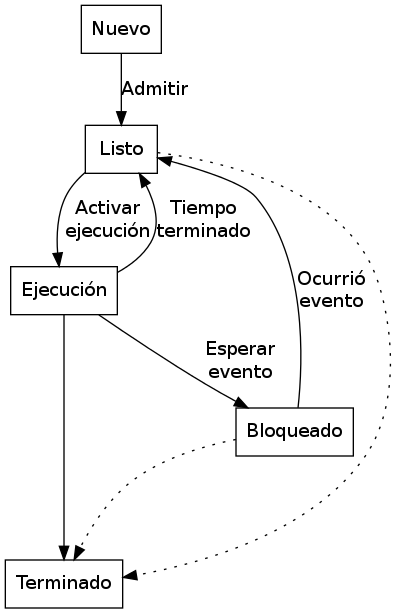
Una disciplina de planificación es no apropiativa si una vez que la CPU ha sido asignada al proceso, ya no se le puede arrebatar. Y por el contrario, es apropiativa, si se le puede quitar la CPU.
La planificación apropiativa es útil en los sistemas en los cuales los procesos de alta prioridad requieren una atención rápida. En los de tiempo real, por ejemplo, las consecuencias de perder una interrupción pueden ser desastrosas. En los sistemas de tiempo compartido, la planificación apropiativa es importante para garantizar tiempos de respuesta aceptables.
La apropiación tiene un precio. El cambio de proceso implica gasto extra. Para que la técnica de apropiación sea efectiva deben mantenerse muchos procesos en memoria principal de manera que el siguiente proceso se encuentre listo cuando quede disponible la CPU. Conservar en memoria principal procesos que no están en ejecución implica gasto extra.
En los sistema no apropiativos, los trabajos largos retrasan a los cortos, pero el tratamiento para todos los procesos es más justo. Los tiempos de respuesta son más predecibles porque los trabajos nuevos de alta prioridad no pueden desplazar a los trabajos en espera.
El Reloj de Interrupciones
Se dice que un proceso está en ejecución cuando tiene asignada la CPU. Si el proceso pertenece al sistema operativo, se dice que el sistema operativo está en ejecución y que puede tomar decisiones que afectan al sistema. Para evitar que los usuarios monopolicen el sistema (deliberadamente o accidentalmente), el sistema operativo tiene mecanismos para arrebatar la CPU al usuario.
El sistema operativo gestiona un reloj de interrupciones que genera interrupciones cada cierto tiempo. Un proceso mantiene el control de la CPU hasta que la libera voluntariamente (acaba su ejecución, o se bloquea), hasta que el reloj interrumpe o hasta que alguna otra interrupción desvía la atención de la CPU. Si el usuario se encuentra en ejecución y el reloj interrumpe, el sistema operativo entra en ejecución para comprobar, por ejemplo, si ha pasado el cuanto de tiempo del proceso que estaba en ejecución.
El reloj de interrupciones asegura que ningún proceso acapare la utilización del procesador. El sistema operativo, apoyándose en él, intenta distribuir el tiempo de CPU entre los distintos procesos ya sean de E/S o de cálculo. Por tanto, ayuda a garantizar tiempos de respuesta para los usuarios interactivos, evitando que el sistema quede bloqueado en un ciclo infinito de algún usuario y permite que los procesos respondan a eventos dependientes de tiempo. Los procesos que deben ejecutarse periódicamente dependen del reloj de interrupciones.
No se debe confundir en ningún caso al reloj de interrupciones con el reloj de la máquina o reloj hardware.
Uso de Prioridades
La mayoría de los algoritmos de planificación apropiativos emplean el uso de prioridades de acuerdo con algún criterio. Cada proceso tiene una prioridad asignada y el planificador seleccionará siempre un proceso de mayor prioridad antes que otro de menor prioridad.
Las prioridades pueden ser asignadas de forma automática por el sistema, o bien se pueden asignar externamente. Pueden ganarse o comprarse. Pueden ser estáticas o dinámicas. Pueden asignarse de forma racional, o de manera arbitraria en situaciones en las que un mecanismo del sistema necesita distinguir entre procesos pero no le importa cuál de ellos es en verdad más importante.
Las prioridades estáticas no cambian. Los mecanismos de prioridad estática son fáciles de llevar a la práctica e implican un gasto extra relativamente bajo. Sin embargo, no responden a cambios en el entorno que podrían hacer necesario un ajuste de prioridades.
Las prioridades dinámicas responden a los cambios. La prioridad inicial asignada a un proceso tiene una corta duración, después se ajusta a un valor más apropiado, a veces deducido de su comportamiento. Los esquemas de prioridad dinámica son más complejos e implican un mayor gasto extra que puede quedar justificado por el aumento en la sensibilidad del sistema.
Algoritmos de planificación
En los siguientes subapartados vamos a estudiar ciertos algoritmos utilizados para planificar la CPU, la elección de uno (o de una mezcla de varios) depende de decisiones de diseño. Antes de exponer los algoritmos vamos a explicar ciertas medidas que se utilizan para evaluarlos.
Porcentaje de utilización de la CPU por procesos de usuario. La CPU es un recurso caro que necesita ser explotado, los valores reales suelen estar entre un 40% y un 90%.
Rendimiento (throughput) = nº de ráfagas por unidad de tiempo. Se define una ráfaga como el período de tiempo en que un proceso necesita la CPU; un proceso, durante su vida, alterna ráfagas con bloqueos. Por extensión, también se define como el nº de trabajos por unidad de tiempo.
Tiempo de espera (E) = tiempo que una ráfaga ha permanecido en estado listo.
Tiempo de finalización (F) = tiempo transcurrido desde que una ráfaga comienza a existir hasta que finaliza. F = E + t (t = tiempo de CPU de la ráfaga).
Penalización (P) = E + t / t = F / t, es una medida dimensional que se puede aplicar homogéneamente a las ráfagas independientemente de su longitud.
En general, hay que maximizar los dos primeros parámetros y minimizar los tres últimos. Sin embargo, estos objetivos son contradictorios, el dedicar más tiempo de CPU a los usuarios se hace a costa de llamar menos al algoritmo de planificación (menos cambios de proceso), y de simplificarlo. Esto provoca que la CPU se reparta menos equitativamente entre los procesos, en detrimento de los últimos tres parámetros.
Así pues, dependiendo de los objetivos se elegirá cierto algoritmo. En los sistemas por lotes suele primar el rendimiento del sistema, mientras que en los sistemas interactivos es preferible minimizar, por ejemplo, el tiempo de espera.
Planificación Primero en Entrar-Primero en Salir (FIFO, First In First Out)
Cuando se tiene que elegir a qué proceso asignar la CPU se escoge al que llevara más tiempo listo. El proceso se mantiene en la CPU hasta que se bloquea voluntariamente.
La ventaja de este algoritmo es su fácil implementación, sin embargo, no es válido para entornos interactivos ya que un proceso de mucho cálculo de CPU hace aumentar el tiempo de espera de los demás procesos . Para implementar el algoritmo sólo se necesita mantener una cola con los procesos listos ordenada por tiempo de llegada. Cuando un proceso pasa de bloqueado a listo se sitúa el último de la cola.
Algunas de las características de este algoritmo es que es no apropiativo y justo en el sentido formal, aunque injusto en el sentido de que: los trabajos largos hacen esperar a los cortos y los trabajos sin importancia hacen esperar a los importantes. Por otro lado es predecible pero no garantiza buenos tiempos de respuesta y por ello se emplea como esquema secundario.
Planficación por Turno Rotatorio (Round Robin).
Este es uno de los algoritmos más antiguos, sencillos y equitativos en el reparto de la CPU entre los procesos, muy válido para entornos de tiempo compartido. Cada proceso tiene asignado un intervalo de tiempo de ejecución, llamado cuantum o cuanto. Si el proceso agota su cuantum de tiempo, se elige a otro proceso para ocupar la CPU. Si el proceso se bloquea o termina antes de agotar su cuantum también se alterna el uso de la CPU. El round robin es muy fácil de implementar. Todo lo que necesita el planificador es mantener una lista de los procesos listos.
Este algoritmo presupone la existencia de un reloj en el sistema. Un reloj es un dispositivo que genera periódicamente interrupciones. Esto es muy importante, pues garantiza que el sistema operativo (en concreto la rutina de servicio de interrupción del reloj) coge el mando de la CPU periódicamente. El cuantum de un proceso equivale a un número fijo de pulsos o ciclos de reloj. Al ocurrir una interrupción de reloj que coincide con la agotación del cuantum se llama al dispatcher.
Tamaño del Cuanto
La determinación del tamaño del cuanto es vital para la operación efectiva de un sistema de cómputo. ¿Debe el cuanto ser pequeño o grande?, ¿fijo o variable?, ¿el mismo para todos los usuarios o debe determinarse por separado para cada uno?
Si el cuanto de tiempo es muy grande, cada proceso tendrá el tiempo necesario para terminar, de manera que el esquema de planificación por turno rotatorio degenera en uno de primero-en-entrar-primero-en-salir. Si el cuanto es muy pequeño, el gasto extra por cambio de proceso se convierte en el factor dominante y el rendimiento del sistema se degradará hasta el punto en que la mayor parte del tiempo se invierte en la conmutación del procesador, con muy poco o ningún tiempo para ejecutar los programas de los usuarios.
¿Exactamente dónde, entre cero e infinito, debe fijarse el tamaño del cuanto? La respuesta es, lo bastante grande como para que la mayoría de las peticiones interactivas requieran menos tiempo que la duración del cuanto.
Pongamos un ejemplo, supongamos que el cambio de proceso tarda 5 mseg., y la duración del cuantum es de 20 mseg.. Con estos parámetros, se utiliza un mínimo del 20% del tiempo de la CPU en la ejecución del sistema operativo. Para incrementar la utilización de la CPU por parte de los procesos de usuario podríamos establecer un cuantum de 500 mseg., el tiempo desperdiciado con este parámetro sería del 1%. Pero consideremos lo que ocurriría si diez usuarios interactivos oprimieran la tecla enter casi al mismo tiempo. Diez procesos se colocarían en la lista de procesos listos. Si la CPU está inactiva, el primero de los procesos comenzaría de inmediato, el segundo comenzaría medio segundo después, etc. Partiendo de la hipótesis de que todos los procesos agoten su cuantum, el último proceso deberá de esperar 4'5 seg. para poder ejecutarse. Esperar 4'5 seg. para la ejecución de una orden sencilla como pwd parece excesivo
En conclusión, un cuantum pequeño disminuye el rendimiento de la CPU, mientras que un cuantum muy largo empobrece los tiempos de respuesta y degenera en el algoritmo FIFO. La solución es adoptar un término medio como 100 mseg.
Planificación por Prioridad al más corto (SJF, Short Job First).
Al igual que en el algoritmo FIFO las ráfagas se ejecutan sin interrupción, por tanto, sólo es útil para entornos batch. Su característica es que cuando se activa el planificador, éste elige la ráfaga de menor duración. Es decir, introduce una noción de prioridad entre ráfagas. Hay que recordar que en los entornos batch se pueden hacer estimaciones del tiempo de ejecución de los procesos.
La ventaja que presenta este algoritmo sobre el algoritmo FIFO es que minimiza el tiempo de finalización promedio, como puede verse en el siguiente ejemplo:
Ej: Supongamos que en un momento dado existen tres ráfagas listos R1, R2 y R3, sus tiempos de ejecución respectivos son 24, 3 y 3 ms. El proceso al que pertenece la ráfaga R1 es la que lleva más tiempo ejecutable, seguido del proceso al que pertenece R2 y del de R3. Veamos el tiempo medio de finalización (F) de las ráfagas aplicando FIFO y SJF:
FIFO F = (24 + 27 + 30) / 3 = 27 ms.
SJF F = (3 + 6 + 30) / 3 = 13 ms.
Se puede demostrar que este algoritmo es el óptimo. Para ello, consideremos el caso de cuatro ráfagas, con tiempos de ejecución de a, b, c y d. La primera ráfaga termina en el tiempo a, la segunda termina en el tiempo a+b, etc. El tiempo promedio de finalización es (4a+3b+2c+d)/4. Es evidente que a contribuye más al promedio que los demás tiempos, por lo que debe ser la ráfaga más corta, b la siguiente, y así sucesivamente. El mismo razonamiento se aplica a un número arbitrario de ráfagas.
No obstante, este algoritmo sólo es óptimo cuando se tienen simultáneamente todas las ráfagas. Como contraejemplo, considérense cinco ráfagas desde A hasta E, con tiempo se ejecución de 2, 4, 1, 1 y 1 respectivamente. Sus tiempos de llegada son 0, 0, 3, 3 y 3. Primero se dispone de A y B, puesto que las demás ráfagas no han llegado aún. Con el algoritmo SJF las ejecutaríamos en orden A, B, C, D, y E con un tiempo de finalización promedio de 4.6. Sin embargo, al ejecutarlas en orden B, C, D, E y A se tiene un promedio de finalización de 4.4.
Planificación por Prioridad al Tiempo Restante más Corto (SRTF, Short Remaining Time First).
Es similar al anterior, con la diferencia de que si un nuevo proceso pasa a listo se activa el dispatcher para ver si es más corto que lo que queda por ejecutar del proceso en ejecución. Si es así el proceso en ejecución pasa a listo y su tiempo de estimación se decrementa con el tiempo que ha estado ejecutándose.
En la figura 6.5 tenemos un ejemplo de funcionamiento del algoritmo en el que se observa cómo se penalizan las ráfagas largas (como en SJF). Un punto débil de este algoritmo se evidencia cuando una ráfaga muy corta suspende a otra un poco más larga, siendo más largo la ejecución en este orden al ser preciso un cambio adicional de proceso y la ejecución del código del planificador.
Planificación a la Tasa de Respuesta más Alta
Brinch Hansen desarrolló la estrategia de prioridad a la tasa de respueta más alta (HRN, highest-response-ratio-next) que corrige algunas deficiencias de SJF, particularmente el retraso excesivo de trabajos largos y el favoritismo excesivo para los trabajos cortos. HRN es un disciplina de planificación no apropiativa en la cual la prioridad de cada proceso no sólo se calcula en función del tiempo de servicio, sino también del tiempo que ha esperado para ser atendido. Cuando un trabajo obtiene el procesador, se ejecuta hasta terminar. Las prioridades dinámicas en HRN se calculan de acuerdo con la siguiente expresión:
prioridad = (tiempo de espera + tiempo de servicio) / tiempo de servicio
Como el tiempo de servicio aparece en el denominador, los procesos cortos tendrán preferencia. Pero como el tiempo de espera aparece en el numerador, los procesos largos que han esperado también tendrán un trato favorable. Obsérvese que la suma tiempo de espera + tiempo de servicio es el tiempo de respuesta del sistema para el proceso si éste se inicia de inmediato.
Planificación por el Comportamiento
Con este tipo de planificación se pretende garantizar al usuario cierta prestación del sistema y tratar de cumplirla. Si en un sistema tenemos 'n' usuarios lo normal será garantizar a cada uno de ellos al menos 1/n de la potencia del procesador. Para ello necesitamos del tiempo consumido por el procesador y el tiempo que lleva el proceso en el sistema. La cantidad de procesador que tiene derecho a consumir el proceso será el cociente entre el tiempo que lleva en el sistema entre el número de procesos que hay en el sistema. A esa cantidad se le puede asociar una prioridad que vendrá dada como el cociente entre tiempo de procesador que ha consumido y el tiempo que se le prometió (el tiempo que tiene derecho a consumir). De tal modo que si esa proporción es de 0'5 significa que tan sólo ha consumido la mitad del tiempo prometido pero si es de 2 quiere decir que ha consumido más de lo debido, justamente el doble.
En sistemas de tiempo real se puede adoptar una variante de este algoritmo en el que se otorgue mayor prioridad al proceso cuyo riesgo de no cumplir el plazo sea mayor.

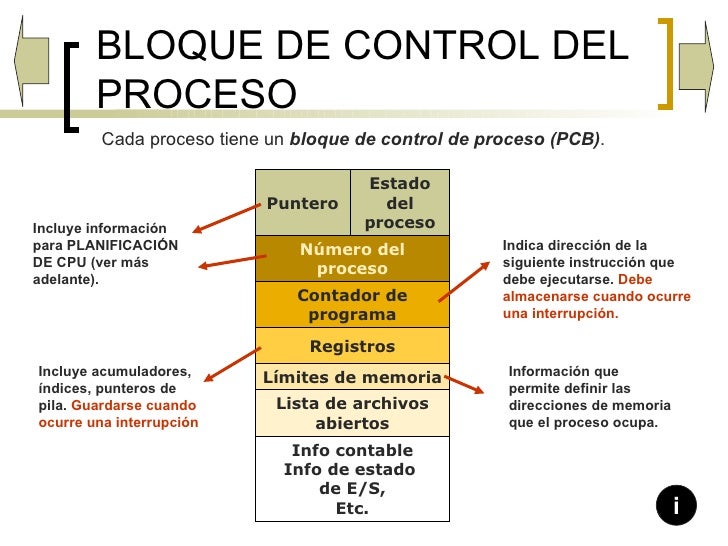 a) de BCP.
a) de BCP.
